

Ever wondered if you could ditch the cloud and run powerful AI models on your own laptop or server? I thought it sounded impossible until I installed Ollama. In just a few hours, I had Llama3.2 up and running locally. I’ll walk you through exactly how I did it, the trade offs I discovered (spoiler: it’s slower than ChatGPT), and how you can build your own custom AI agents without breaking the bank.
System Requirements & Speed Considerations
Before diving in, let me share why this matters. I tried running a 32 billion parameter model on a high end gaming laptop with a Nvidia 3080 GPU and it was still painfully slow.
A better setup I found was to use a mini-pc with integral cpu/gpu chip as this will use RAM. It’ll be even slower but you don’t need a dedicated GPU with massive memory.
You can then queue up requests using AI agents and custom scripts to run overnight or to automate certain things.
If your goal is fast, use ChatGPT or Deepseek or Claude. But for casual experimentation or development, you can absolutely start on a laptop or small home server type setup.
Ollama Installation Instructions
The easiest way to install Ollama is to do it via the command line. Install Ollama using macOS, Linux, or Windows WSL:
curl -fsSL https://ollama.com/install.sh | sh
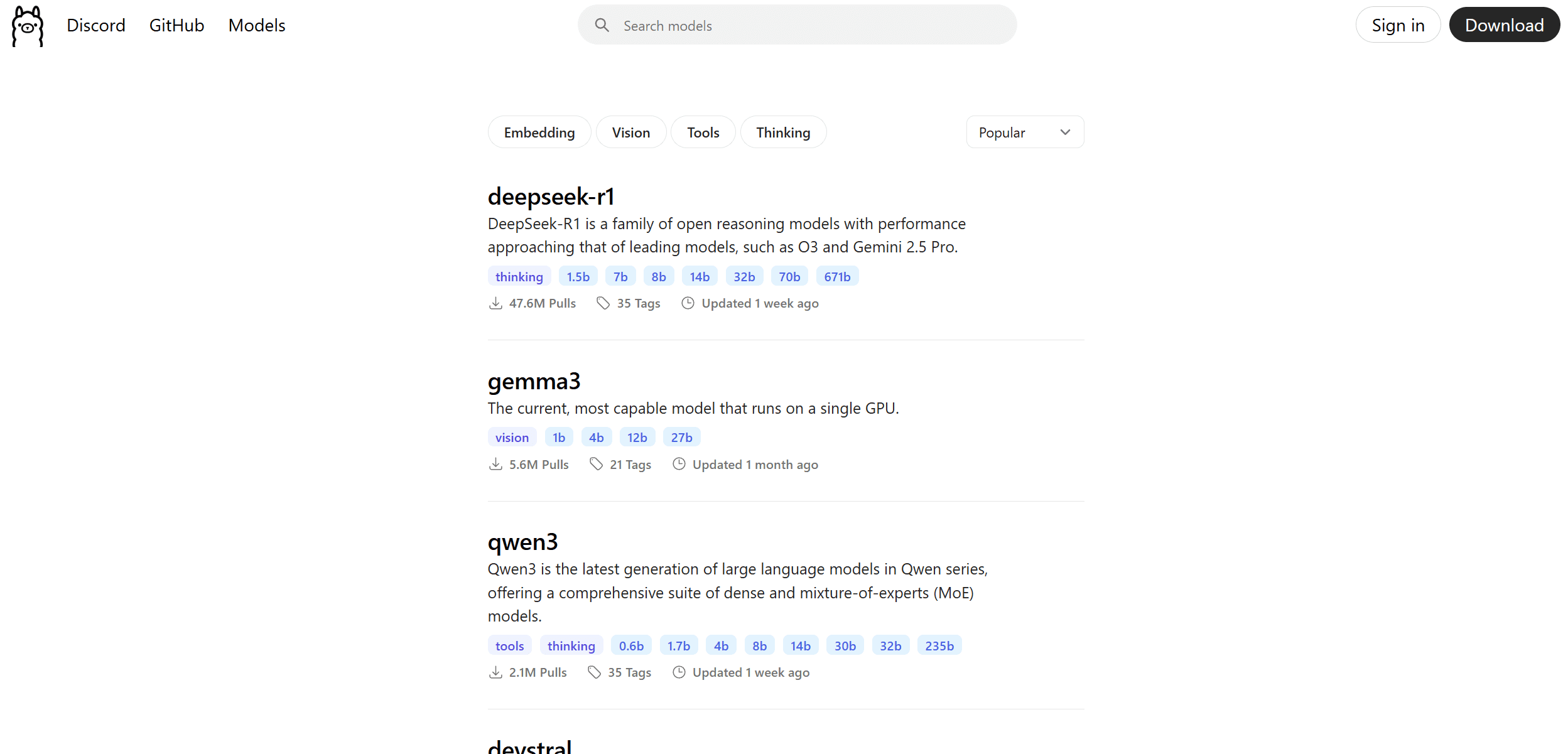
ollama pull deepseek-r1This installs the CLI, server, and auto detects GPU options. Then we pull in the latest deepseek-r1 model.
You can get a full list of models available here: https://ollama.com/search
We can then run it locally with the command:
ollama run deepseek-r1You’ll get an REPL to chat with. Thanks to auto GPU detection, the model runs on whatever’s available.
What Sized Models Can I Run?
You want scale, I get it. Here’s what I’ve tested successfully:
- 7B: Comfortable with 8GB RAM or 8GB VRAM
- 13B: Requires ~16GB RAM or a solid GPU
- 30-40B: Needs 32+GB RAM and/or highend GPUs
In benchmarks on a Nvidia RTX4090 13B models ran at ~70 tokens/sec using ~65% VRAM. 40B models still ran but slowed to ~8 tokens/sec due to VRAM limits
Note that some models are optimized for smaller home devices. Checkout Gemma3 for example that is designed for single GPU.
https://ollama.com/library/gemma3
How to Integrate with Custom AI Agents
The biggest benefit to running AI models locally is that you can rereoute AI Agent queries that aren’t time sensitve from the OpenAI API directly to Ollama.
Ollama includes a built in API on localhost:11434. Use it like:
curl -X POST http://localhost:11434/api/chat \
-d '{ "model": "deepseek-r1", "messages": [{"role":"user","content":"Teach Me Something About Bitcoin"}] }'Powerful stuff, and completely local. No API keys, no Monthly memberships required.
If you’re building something unique, wanting full model control, or just tinkering, this is the ultimate sandbox. Give it a spin you won’t regret owning your AI infrastructure.
