

Scraping Twitter/X without direct API access can be accomplished by leveraging third-party services like RapidAPI, which provides a streamlined way to interact with Twitter data. In this tutorial, we’ll walk through the process of using RapidAPI to scrape tweets from a specified user. I’m going to provide code snippets in Python and NodeJS for this task but you can convert it to any coding language capable of making https requests.
Set up an account with RapidAPI and subscribe to a free service (limited requests) for one of the Twitter scrapers such as this one: https://rapidapi.com/omarmhaimdat/api/twitter154
This will give you an API key (X-RapidAPI-Key) which you will need to insert in the code snippets below.
Python Twitter Scraper
import http.client
conn = http.client.HTTPSConnection("twitter154.p.rapidapi.com")
payload = "{\"username\":\"james_bachini\",\"include_replies\":false,\"include_pinned\":false}"
headers = {
'x-rapidapi-key': "<YOUR_RAPIDAPI_KEY>",
'x-rapidapi-host': "twitter154.p.rapidapi.com",
'Content-Type': "application/json"
}
conn.request("POST", "/user/tweets", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))The http.client module is part of Python’s standard library, so you don’t need to install it separately. However, make sure you have Python 3 installed.
NodeJS Twitter Scraper
cconst https = require('https');
const getTweets = async (username) => {
const options = {
hostname: 'twitter154.p.rapidapi.com',
path: `/user/tweets?username=${username}&include_replies=false&include_pinned=false`,
method: 'GET',
headers: {
'x-rapidapi-key': '<YOUR_RAPIDAPI_KEY>',
'x-rapidapi-host': 'twitter154.p.rapidapi.com'
}
};
return new Promise((resolve, reject) => {
const req = https.request(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
resolve(data);
});
});
req.on('error', (e) => {
reject(e);
});
req.end();
});
};
const fetchTweets = async (username) => {
try {
const result = await getTweets(username);
console.log(result);
} catch (error) {
console.error(error);
}
};
fetchTweets('james_bachini');
We need to install nodejs and then save the file above to xScraper.js and edit line 9 to enter your API key, run the script
node xScraper.jsAnd you will get the jSON output like below. From this you can format it and do whatever you want with the tweets.
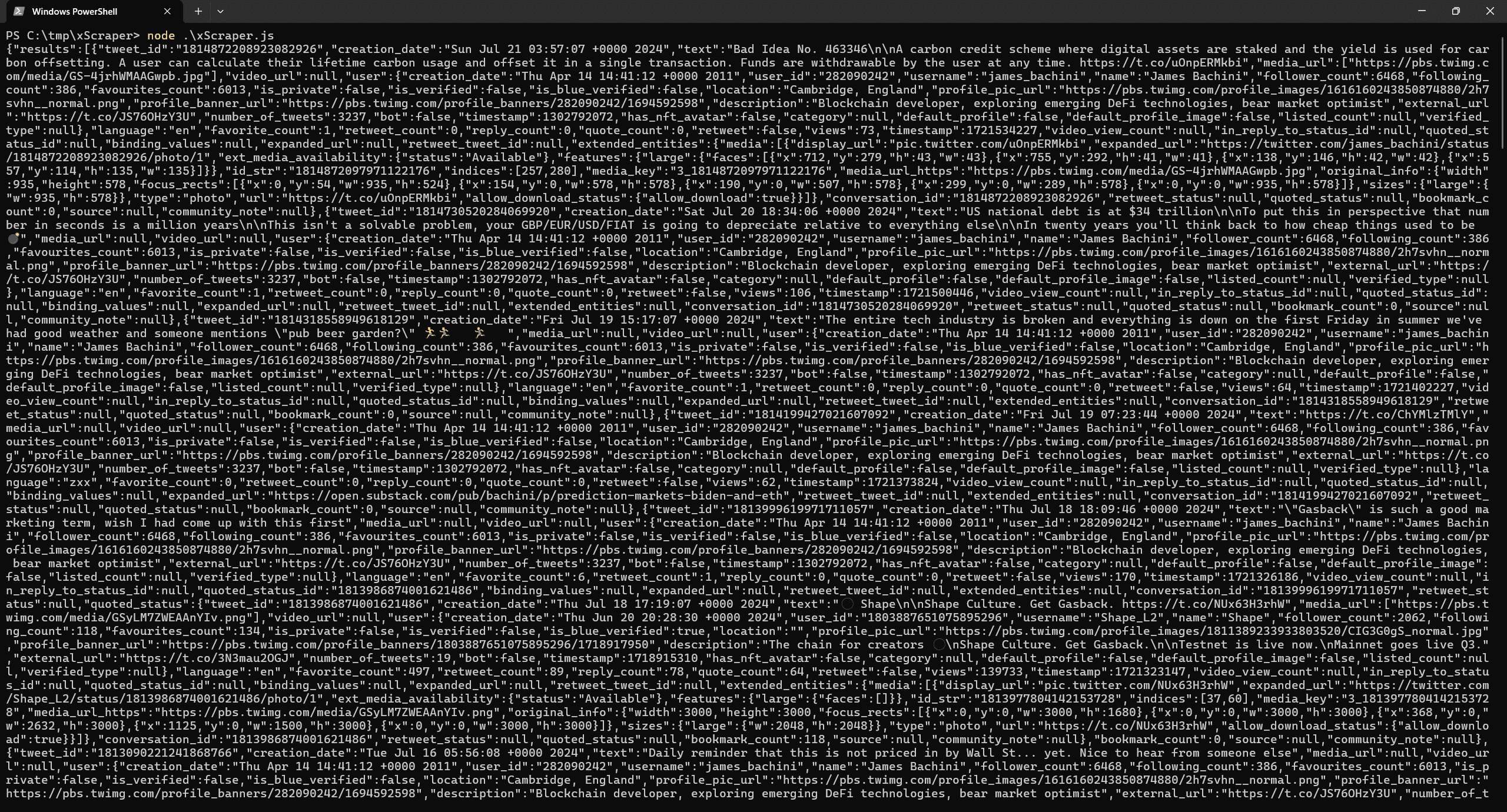
Further Development
This code just uses a single endpoint to get tweets by user handle. There are a whole library of endpoints that developers can use within the scraping tools. Such as:
- Get Tweets by User ID – Retrieve tweets for a specified user by their user ID.
- Get Followers by User ID – Retrieve a list of followers for a specified user by their user ID.
- Get Followings by User ID – Retrieve a list of users that a specified user is following by their user ID.
- Get User Details by User ID – Retrieve detailed information about a user by their user ID.
- Get Tweets by Username – Retrieve tweets for a specified user by their username.
- Get Followers by Username – Retrieve a list of followers for a specified user by their username.
- Get Followings by Username – Retrieve a list of users that a specified user is following by their username.
- Get User Details by Username – Retrieve detailed information about a user by their username.
- Search Tweets – Search for tweets based on a query.
- Get Tweet Engagements – Retrieve engagement metrics for a specified tweet by its ID.
I hope this Twitter X scraping tutorial is of interest and you can use it for fun and profit.
